交换排序就是通过比较交换实现排序。分冒泡排序和快速排序两种。
一、冒泡排序:
1、简述
顾名思义就是大的就冒头,换位置。
通过多次重复比较、交换相邻记录而实现排序;每一趟的效果都是将当前键值最大的记录换到最后。
冒泡排序算法的原理如下:
- 比较相邻的元素。如果第一个比第二个大,就交换他们两个。
- 对每一对相邻元素做同样的工作,从开始第一对到结尾的最后一对。在这一点,最后的元素应该会是最大的数。
- 针对所有的元素重复以上的步骤,除了最后一个。
- 持续每次对越来越少的元素重复上面的步骤,直到没有任何一对数字需要比较
2、复杂度
时间复杂度:O(n²)
空间复杂度:O(1)
3、稳定性:稳定排序
4、例子
#include <iostream>
using namespace std;
// 冒泡
int main() {
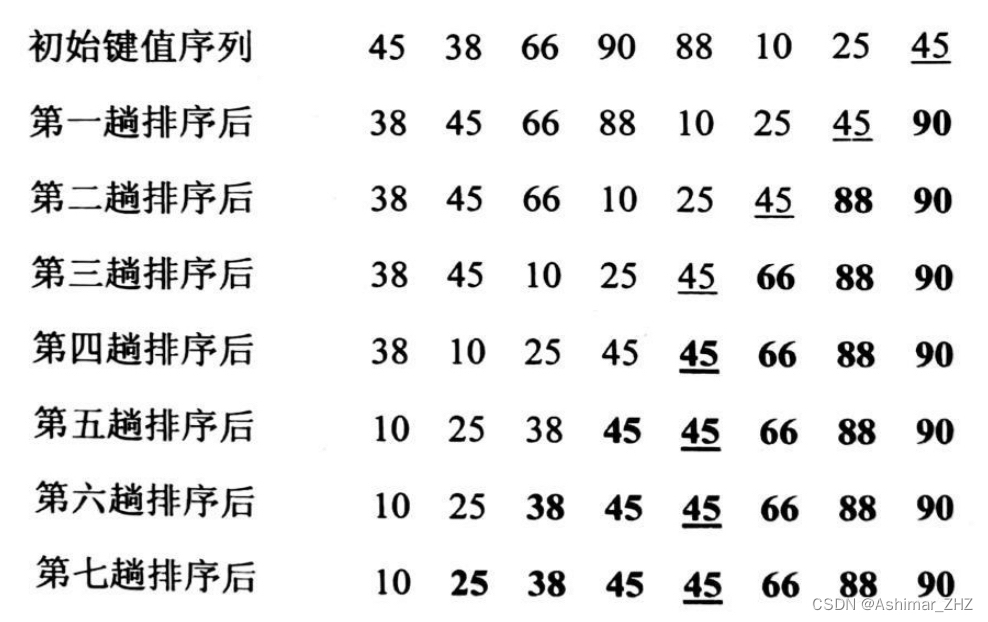
int arr[8] = {45, 38, 66, 90, 88, 10, 25, 45};
int arrCount = sizeof(arr) / sizeof(arr[0]);
for (int i = 0; i < arrCount - 1; i++) {
for (int j = 0; j < arrCount - i - 1; j++) {
if (arr[j] > arr[j+1]) { // 对比两个值
int tmp = arr[j];
// 交换位置
arr[j] = arr[j+1];
arr[j+1] = tmp;
}
}
cout<<i+1<<"次排序后:";
for (int i = 0;i < arrCount;i++) {
cout << arr[i] << " ";
}
cout<<endl;
}
cout<<"最后结果:";
for (int i = 0;i < arrCount;i++) {
cout << arr[i] << " ";
}
return 0;
}输出结果:
1次排序后:38 45 66 88 10 25 45 90
2次排序后:38 45 66 10 25 45 88 90
3次排序后:38 45 10 25 45 66 88 90
4次排序后:38 10 25 45 45 66 88 90
5次排序后:10 25 38 45 45 66 88 90
6次排序后:10 25 38 45 45 66 88 90
7次排序后:10 25 38 45 45 66 88 90
最后结果:10 25 38 45 45 66 88 90二、快速排序:
关键词:基准值,递归算法
1、简述
快速排序(Quicksort),计算机科学词汇,适用领域Pascal,C++等语言,是对冒泡排序算法的一种改进。
快速排序算法流程如下:
- 首先设定一个基准值,通过该基准值将数组分成左右两部分。
- 将大于或等于基准值的数据集中到数组右边,小于基准值的数据集中到数组的左边。此时,左边部分中各元素都小于基准值,而右边部分中各元素都大于或等于基准值 。
- 然后,左边和右边的数据可以独立排序。对于左侧的数组数据,又可以取一个基准值,将该部分数据分成左右两部分,同样在左边放置较小值,右边放置较大值。右侧的数组数据也可以做类似处理。
- 重复上述过程,可以看出,这是一个递归定义。通过递归将左侧部分排好序后,再递归排好右侧部分的顺序。当左、右两个部分各数据排序完成后,整个数组的排序也就完成了。
2、复杂度
时间复杂度:O() 、最差O(n²) (注:快速排序在表基本有序时,最不利于其发挥效率,即蜕化为冒泡排序,其时间复杂度为O(n²))
空间复杂度:O()
3、稳定性:不稳定排序
在交换的过程中相同的数值可能会被换到前面去,所以是不稳定的。
4、例子
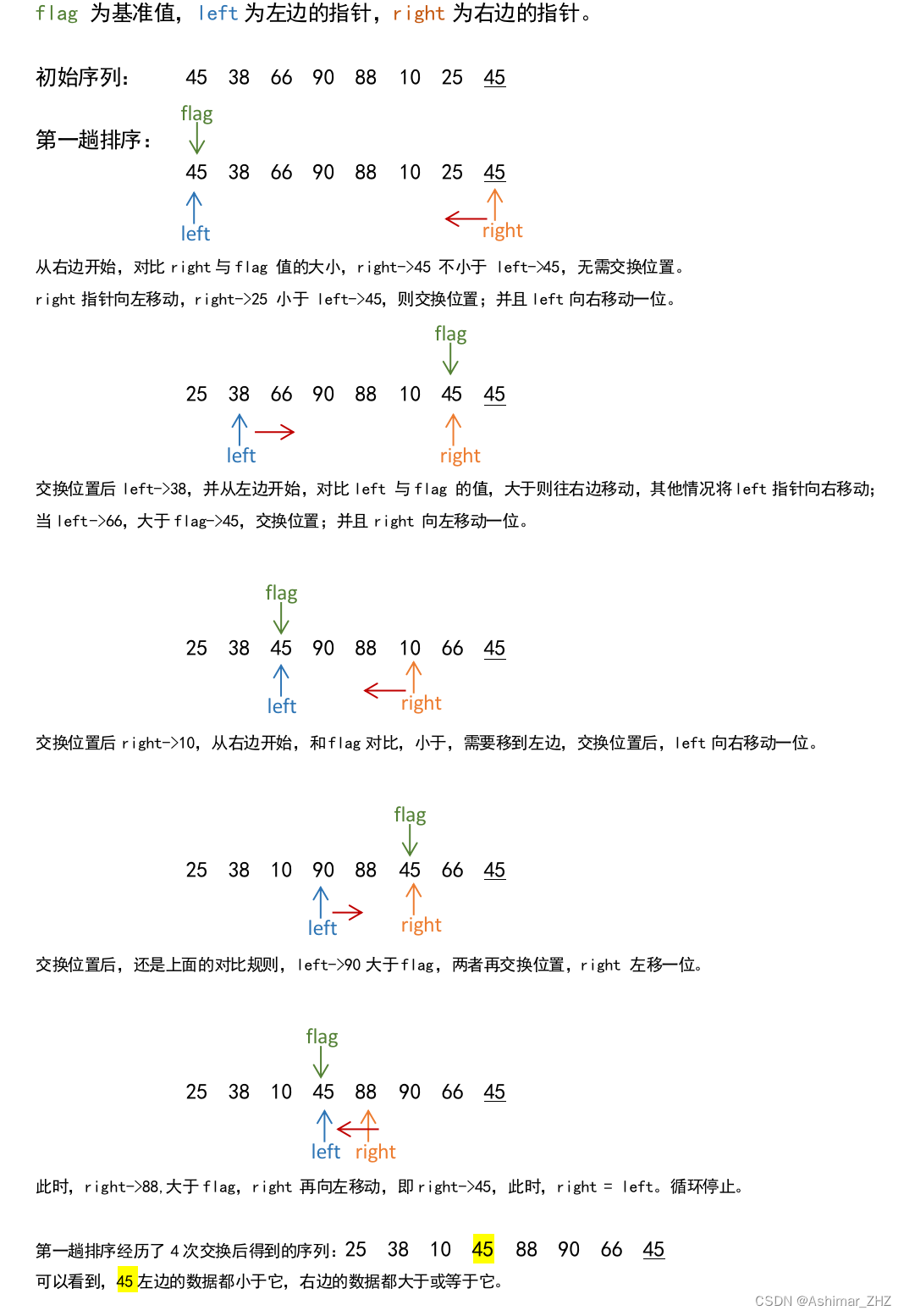
在经历第一趟之后,我们将基准值左边和右边分别进行同样的操作。
left和right从原先的0和7,更新为对应的数值:
第一趟排序之后: [25 38 10] 45 [88 90 66 45]
分别对子序列排序:
左边子序列排序: [25 38 10] > left = 0, right = 2, flag = 25
[10] 25 [38]
再对25左右两侧进行同样的排序方式,得出左边子序列排序后的结果:
10 25 38
右边子序列排序: [88 90 66 45] > left = 4, right = 7, flag = 88
[45 66] 88 [90]
再对88左右两侧进行同样的排序方式,最后得到右边子序列排序后的顺序 :
45 66 88 90
合并起来就是: [10 25 38 45 45 66 88 90]
由于交换规则一致,我们可以用递归来处理。
#include <iostream>
using namespace std;
/// 交换位置
void swapPosition(int arr[], int x, int y) {
arr[x] = arr[y]+arr[x];
arr[y] = arr[x] - arr[y];
arr[x] = arr[x] - arr[y];
}
void quickSort(int list[], int begin, int end) {
// 将基准值flag定为列表第一个。
int left = begin, right = end, flag = list[begin];
cout<<"这趟排序的起始位置:"<<begin<<",结束位置:"<<end<<",基准值:"<<flag<<endl;
// 左右指针未碰头则反复做:
while (left < right) {
// 从右边开始!!!
// 右边没找到小于 flag 的右指针 继续往左移
while (list[right] >= flag && left<right) {
--right;
}
// 右边找到比flag小的数据,则将其送到左边,并且将左边的指针往右移动
if(left < right) {
// 交换位置
swapPosition(list, left, right);
++left;
}
// 接着开始左边的循环
// 左边没找到大于 flag 的左指针 继续往右移
while (list[left] <= flag && left<right) {
++left;
}
// 左边找到比flag大的数据,则将其送到右边,并且将右边的指针往左移动
if(left < right) {
// 交换位置
swapPosition(list, left, right);
--right;
}
}
cout<<"结果:";
for (int i = 0;i < 8;i++) {
cout << list[i] << " ";
}
cout<<endl;
if (begin<left-1)
{
cout<<"开始左边的递归:"<<endl;
quickSort(list, begin, left-1);
}
if(right+1 < end)
{
cout<<"开始右边的递归:"<<endl;
quickSort(list, right+1, end);
}
}
int main() {
int arr[8] = {45, 38, 66, 90, 88, 10, 25, 45};
int arrCount = sizeof(arr) / sizeof(arr[0]);
quickSort(arr, 0, arrCount - 1);
cout<<"最后结果:";
for (int i = 0;i < arrCount;i++) {
cout << arr[i] << " ";
}
return 0;
}
输出结果:
这趟排序的起始位置:0,结束位置:7,基准值:45
结果:25 38 10 45 88 90 66 45
开始左边的递归:
这趟排序的起始位置:0,结束位置:2,基准值:25
结果:10 25 38 45 88 90 66 45
开始右边的递归:
这趟排序的起始位置:4,结束位置:7,基准值:88
结果:10 25 38 45 45 66 88 90
开始左边的递归:
这趟排序的起始位置:4,结束位置:5,基准值:45
结果:10 25 38 45 45 66 88 90
最后结果:10 25 38 45 45 66 88 90参考:
百度百科——冒泡排序:https://baike.baidu.com/item/%E5%86%92%E6%B3%A1%E6%8E%92%E5%BA%8F?fromModule=lemma_search-box
百度百科——快速排序:https://baike.baidu.com/item/%E5%BF%AB%E9%80%9F%E6%8E%92%E5%BA%8F%E7%AE%97%E6%B3%95/369842?fr=ge_ala
生命不息,学习不止,若有不正确的地方,欢迎指正。